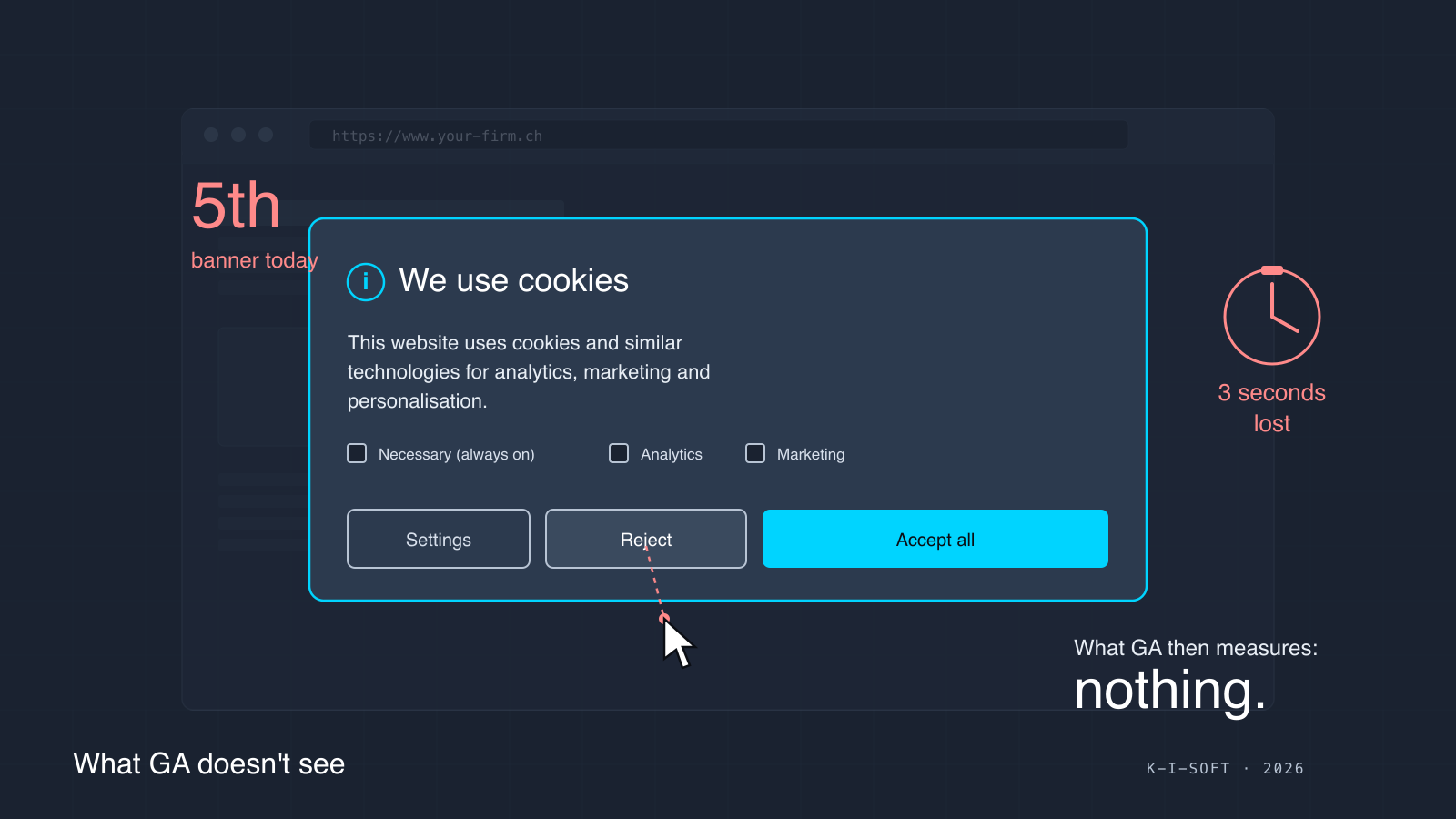
Early May, a Treuhänder opens his Google Analytics dashboard. April: 412 sessions, an average session duration of four hours that looks implausibly high, a handful of contact-form clicks. He knows that at least three new clients came in through the website in April. Not one of them appears.
The usual explanation is that GA is misconfigured, or that it is time to pick a new tracking tool. Neither is usually true. What has changed is not the tools, but the world around them.
This post explains three things, without tipping into tool recommendations or sales copy. First, why a modern website structurally fails to show a growing share of its visitors in Google Analytics. Second, where that gap comes from, in three clearly separable causes with current numbers. And third, what honest measurement can deliver without replacing GA.
What has changed, in three sentences
Five years ago, Google Analytics could capture almost every visitor. Today, across the DACH region a good half of all visitors reject the consent banner, Safari and Firefox block tracking by default anyway, and AI crawlers like GPTBot or ClaudeBot run no JavaScript and appear in no statistic. GA itself is not wrong. GA only measures what it is allowed to, and able to.
Not knowing this leads straight into a professional trap. Owners make decisions about content and investment on a data base that is systematically too small. Marketing agencies deliver monthly reports that miss exactly the visitors who increasingly decide how visible a brand is. And technical clients build conversion funnels that rest on data points which have been drifting downward for years.
What exactly is required, briefly
Before the three causes, a short legal context. It explains why the consent banner is there at all today, and why the rejection rates look the way they do.
In Germany, the General Data Protection Regulation has applied since 2018. With the 2020 Federal Court ruling on Planet49 and the TTDSG (today TDDDG) in force since 2022, the picture is clear: non-essential cookies such as Google Analytics, advertising pixels or marketing tools may only be set once the visitor has actively agreed. In Switzerland, the revised Data Protection Act (FADP) has applied since September 2023. On cookie consent it is less strict than the GDPR and in many cases requires only information rather than active consent. Swiss websites that have visitors from the EU still work with GDPR-compliant opt-in in practice, because they fall under both regimes.
Active consent means the visitor has to click the “Accept” button deliberately. A banner clicked away silently does not count. Dismissing it without a choice does not count. Ignoring the banner and scrolling on does not count. And pre-ticked checkboxes have been expressly invalid since the Planet49 ruling. Anyone who clicks “Reject”, or makes no choice, is not captured by GA or any comparable tool, and that is not a configuration problem of the website but the legally intended consequence.
Important for the rest of this post: the “Reject” button has to be the same size, equally prominent, and visible on the first layer of the banner. Hidden or smaller reject options count as invalid consent and carry a fine risk. The French regulator CNIL fined Google 150 million euros and Facebook 60 million in 2022, partly for this reason.
First cause: the consent banner
Since the GDPR took effect in 2018, and with the adjusted Swiss reading of the revised FADP, non-essential cookies in the DACH region may only be set after explicit consent. Google Analytics is one of them. Anyone who does not accept the banner is not captured by GA, and the trend of recent years points clearly in one direction.
An overview of 26 banner studies from Europe shows the trajectory: in 2018, between 60 and 90 percent of visitors clicked “Accept all”, often for lack of a real alternative. From 2021, rejection rates climbed to 40 to 50 percent once banners had to show a visible “Reject” button. In the current studies from 2024 and 2025, half to two thirds reject when the banner is built correctly. One German survey reports that by now around 52 percent of websites show an equally visible “Reject” button, which pushes the rejection rate up further.
For Swiss websites the situation is structurally identical. A behavioural study by Advance Metrics from 2023 compares clicking behaviour across several countries and finds that users in Germany and Switzerland react to banners in comparable ways, with a slight tendency toward even more reticent behaviour in Switzerland. So anyone who reports a consent rate of 50 percent or less in a realistic monthly report for a Swiss SME is not wrong, but realistic.
Important: this effect is not the result of a poorly configured website. It is the legally intended consequence of an opt-in model that works. Anyone who softens the banner again with dark patterns, for instance through hidden reject options, does not only invite a fine risk. The gain is also only short-term: the measurable dent in visitor trust usually costs more than the few percentage points of consent.
In practice this means: count on at least half of all visitors never appearing in GA, even when everything is configured correctly.
Second cause: browsers that block tracking by default
The second layer is technical and lies outside the site operator’s control. Safari and Firefox have had built-in tracking protection for years: Intelligent Tracking Prevention (Apple) and Enhanced Tracking Protection (Mozilla). Both block third-party cookies by default and sharply limit the lifetime of first-party cookies. Despite all its adjustments, GA still works partly on a cookie basis and therefore loses data points even when the visitor has agreed to the banner.
The share of these browsers varies a lot by region and audience. In B2B settings with a high Apple share (law firms, design agencies, Treuhand offices, architecture practices) the Safari share is often above 30 percent. For these visitors GA measures structurally less accurately.
This is not a theoretical claim. The effects are documented and acknowledged by every CMP vendor as well as by Google itself. Google responded with “Consent Mode v2”, a modelling approach that statistically estimates missing data points. Modelled data is an approximation, not a substitute for real measurement.
Third cause: AI crawlers GA never sees
The third layer is the newest and, for the coming years, by far the most important. It concerns not people but machines that read websites in order to generate answers in AI chats. Ask ChatGPT “which Treuhänder are there in Bern” and you get an answer based on websites that a crawler read beforehand and made available to a language model. Anyone who does not appear there simply does not exist for the growing number of people who no longer start their search at Google.
These crawlers are called GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, AppleBot-Extended and a few others. They are not a fringe phenomenon. GPTBot alone generated 569 million requests within one month on Vercel’s network, with Anthropic’s Claude following at 370 million. Together that is around 20 percent of the volume of Googlebot, which made 4.5 billion requests in the same period. The trend is climbing steeply.
Here is the point that matters for site operators. These crawlers do not show up in Google Analytics. GA measures people, not machines, and relies on JavaScript execution. Vercel and MERJ analysed more than 500 million GPTBot fetches and found JavaScript execution not a single time. The same holds for ClaudeBot, PerplexityBot, Meta’s ExternalAgent and Bytespider. These bots load the page, sometimes even fetch JavaScript files, but they do not run the code. They read the raw HTML and nothing else.
For technical readers: this has a direct consequence for architecture decisions. A pure single-page application that only renders its content after hydration in the browser is invisible to these bots. The content of a client-side-rendered React, Vue or Angular app does not exist as far as the AI crawlers are concerned. Not “poorly indexed”. Not “partially visible”. Invisible. Server-side rendering, static site generation, or a hybrid like Astro with selective hydration is no longer just an SEO optimisation, but a precondition for appearing in AI-driven search at all. Google’s own crawler is the one relevant exception; it renders JavaScript through a two-stage indexing process. Bing renders partially. Everyone else reads static HTML, and that is where the story ends.
For owners and marketing agencies: this point is not academic. When a modern search (“best Treuhand firm for GmbHs in Bern”) no longer starts at Google but in ChatGPT or Perplexity, what counts is no longer how well the site ranks in Google’s result list, but whether AI models have read it at all. The only reliable way to check that is the website’s server logs. Google Analytics does not show this traffic, by design.
What the gap actually means
Three effects follow from the three causes, all of them real and measurable on any typical SME website.
First: the visitor count reported in GA is a lower bound, not the actual traffic. In a realistic scenario with a correct consent banner and around 30 percent Apple share, the actual traffic is two to three times higher than the GA figure. That is not a “maybe”, it is a number you can read off the server logs.
Second: conversion rates in GA often look better than they are. Anyone who calculates conversion against 100 GA sessions but in truth had 200 visitors misreads their actual funnel. For marketing budgets that means the cost per real visitor is usually lower than reported, but the conversion rate is lower too.
Third: AI-crawler visibility cannot be represented in GA at all. Anyone who wants to know whether ChatGPT has read their website cannot find that out in GA, neither through a different setup nor through a different tool that is based on JavaScript.
What honest measurement can deliver
Anyone who wants to close these gaps without replacing GA has exactly one reliable option: server-side measurement. Every call to a website passes a server first. Before JavaScript is loaded, a banner shown or a cookie set, there is an HTTP request that arrives on the operator’s side. This request is logged regardless of consent, browser setting or JavaScript capability. It captures human and machine alike.
For technical readers: in a typical modern architecture this request arrives at a CDN. On AWS this CDN is called CloudFront; comparable services are Cloudflare or Fastly. All three offer standard access logs that record every request with a timestamp, IP address (shortened or hashed for data minimisation), HTTP status, URL and user agent. These logs land in object storage (on AWS, in S3) and can either be moved into a database like DynamoDB via a Lambda function or queried directly with tools such as AWS Athena.
This architecture has three properties that are especially relevant for SMEs. First, it is data-minimising. No personal data flows in the sense that GA processes it, no cookies, no fingerprinting. The logs show what kind of request hit which URL, not “Anna from Bern visited the site”. That largely takes it out of the typical consent-required scope of the GDPR and the revised FADP, an assessment that your data protection officer naturally has to confirm for the specific case.
Second, it is cheap. The storage cost for CloudFront logs of an SME website is typically under one franc a month. Processing costs a few francs more, depending on volume.
Third, it is complete in the way GA is not. Every single call appears, whether it comes from a human or a bot, with or without consent. What the logs do not show is behavioural data within the page: clicks, scroll depth, time on page. For that you still need a client-side tool, and for that Google Analytics, even after all its limitations, remains a good standard.
What server-side measurement does not replace
So that no wrong impression forms: server logs are not a magic bullet and do not replace a full analytics setup. What they cannot do:
They do not measure behaviour within a page. Anyone who wants to know how long someone read, where they clicked away, or whether they filled in a form halfway and then abandoned it still needs a tool that runs in the browser, with all the consent implications that brings.
They do not deliver ready-made funnels. Anyone who wants to evaluate a campaign funnel from ad to conversion still needs GA or a comparable tool.
They do not replace the Google Ads or LinkedIn conversion tracking required to optimise paid advertising.
Server logs are a second layer alongside GA, not a replacement. They close the gap GA has by design, and they deliver the blind spot that no configuration and no switch of analytics tool can fix.
Practical first steps
Three steps that make sense for most SMEs, regardless of how deep the current setup is.
First: take one sober look at your own consent banner. Does it have a visible “Reject” button that is the same size and equally prominent as the “Accept” button? If not, the website is formally vulnerable, and the mid-range fine risk runs from four to five figures. If yes: then GA capturing under 50 percent is normal, and not a configuration problem.
Second: take one sober look at the content of the website, the way an AI crawler sees it. In Chrome, right-click and choose “View page source” to open the raw HTML. If the actual content is missing there and you only see an empty <div id="root"></div> with scripts, then the website is invisible to every AI crawler. That is fixable, but it is worth knowing whether the problem exists before any follow-up conversation with an agency or developer.
Third: have one conversation with your technical partner (agency, developer, IT provider) about whether the website renders its content server-side or client-side, and whether the server logs are accessible and analysable. If not, that is no disaster, but it is an architecture decision that can be changed with a few months’ lead time. Anyone who wants to appear in AI searches in two years should ask the question now.
I have summarised the key points of this post on a single page: what Google Analytics does not see, and where the missing half becomes visible instead. As a PDF to print or pass on. The current version is in German.
→ Download PDF: K-I-Soft reference “What GA doesn’t see” (in German)
What you see once you measure
A short anecdote to close, which is also a test. Anyone who looks at their own logs for the first time typically sees three things that were never visible in GA. A layer of competitive analysis: other websites, often direct competitors, whose crawlers pull your site regularly. A layer of AI preparation: GPTBot, ClaudeBot, PerplexityBot collecting content for the next training or answer round. And a layer of genuine human interest that never consented, but did click the banner, and lives in GA as “not captured”.
Most owners and agencies who have seen this once do not go back to the GA-only view. Not because GA is wrong, but because they have understood that GA has for years measured exactly the half it is allowed to measure, and that the other half is moving down there in the logs, visible to anyone who looks.
Sources
- Vercel: “The rise of the AI crawler” (volume of GPTBot/Claude/Googlebot, monthly request figures): https://vercel.com/blog/the-rise-of-the-ai-crawler
- Vercel/MERJ methodology (measurement setup with edge middleware and a web-rendering monitor): https://vercel.com/blog/how-google-handles-javascript-throughout-the-indexing-process
- Vercel/MERJ: AI-crawler JavaScript analysis (500 million fetches, zero execution): https://vercel.com/blog/the-rise-of-the-ai-crawler
- Advance Metrics: “Cookie Behaviour Study, 5 years after GDPR” (DACH comparison, cookie behaviour in Germany and Switzerland): https://www.advance-metrics.com/en/blog/cookie-behaviour-study/
- Ignite Video: overview of 26 European banner studies (development of rejection rates 2018 to 2025): https://www.ignite.video/en/articles/basics/cookie-consent-studies
- CookieYes: “Cookie Consent Trends by Country 2026” (country comparison of rejection rates, fine context): https://www.cookieyes.com/blog/cookie-consent-trends/
- Searchviu: “AI Crawlers & JavaScript Rendering 2025” (comparison of crawler behaviour GPTBot vs. ClaudeBot vs. PerplexityBot): https://www.searchviu.com/en/ai-crawlers-javascript-rendering/
This post is the deep-dive companion to “Who visits you” on the home page. If you want to see your own server logs once, you’ll find a link to the 30-minute call on the site.