Ein Treuhänder schaut Anfang Mai in sein Google-Analytics-Dashboard. April: 412 Sitzungen, vier Stunden durchschnittliche Sitzungsdauer wirkt unrealistisch hoch, eine Hand voll Kontaktformular-Klicks. Er weiss, dass im April mindestens drei Neukunden über die Webseite gekommen sind. Davon erscheint keiner.
Die übliche Erklärung lautet, dass GA falsch konfiguriert sei oder ein neues Tracking-Tool ausgewählt werden müsse. Beides trifft selten zu. Was sich verändert hat, sind nicht die Werkzeuge, sondern die Welt um sie herum.
Dieser Beitrag erklärt drei Dinge, ohne in Tool-Empfehlungen oder Verkaufstexte zu kippen. Erstens, warum eine moderne Webseite einen wachsenden Teil ihrer Besucher prinzipbedingt nicht in Google Analytics zeigt. Zweitens, woher diese Lücke kommt, in drei klar trennbaren Ursachen mit aktuellen Zahlen. Und drittens, was eine ehrliche Messung leisten kann, ohne GA abzulösen.
Was sich verändert hat, in drei Sätzen
Vor fünf Jahren konnte Google Analytics fast jeden Besucher erfassen. Heute lehnt im DACH-Raum gut die Hälfte aller Besucher den Consent-Banner ab, Safari und Firefox blockieren das Tracking ohnehin von Haus aus, und KI-Crawler wie GPTBot oder ClaudeBot führen kein JavaScript aus und erscheinen in keiner Statistik. GA selbst ist nicht falsch, GA misst nur das, was es messen darf und kann.
Wer das nicht weiss, läuft in eine berufliche Falle. Geschäftsführer treffen Entscheidungen über Inhalte und Investitionen auf einer Datenbasis, die systematisch zu klein ist. Marketing-Agenturen liefern Monatsberichte, in denen genau die Besucher fehlen, die zunehmend über die Sichtbarkeit der Marke entscheiden. Und technische Auftraggeber bauen Conversion-Funnel, die sich auf Datenpunkte stützen, die seit Jahren systematisch nach unten driften.
Was genau Pflicht ist, kurz
Bevor wir zu den drei Ursachen kommen, ein kurzer Rechts-Kontext. Er erklärt, warum der Consent-Banner heute überhaupt da ist und warum die Ablehnungsraten so aussehen, wie sie aussehen.
In Deutschland gilt seit 2018 die Datenschutz-Grundverordnung. Mit dem 2020er BGH-Urteil zu Planet49 und dem ab 2022 geltenden TTDSG (heute TDDDG) ist klar: nicht-essentielle Cookies wie Google Analytics, Werbe-Pixel oder Marketing-Tools dürfen erst dann gesetzt werden, wenn der Besucher dem aktiv zugestimmt hat. In der Schweiz gilt seit September 2023 das revidierte DSG. Es ist beim Cookie-Consent weniger streng als die DSGVO und verlangt in vielen Fällen nur Information statt aktiver Zustimmung. Schweizer Webseiten, die Besucher aus der EU haben, arbeiten in der Praxis trotzdem mit DSGVO-konformem Opt-in, weil sie unter beide Regimes fallen.
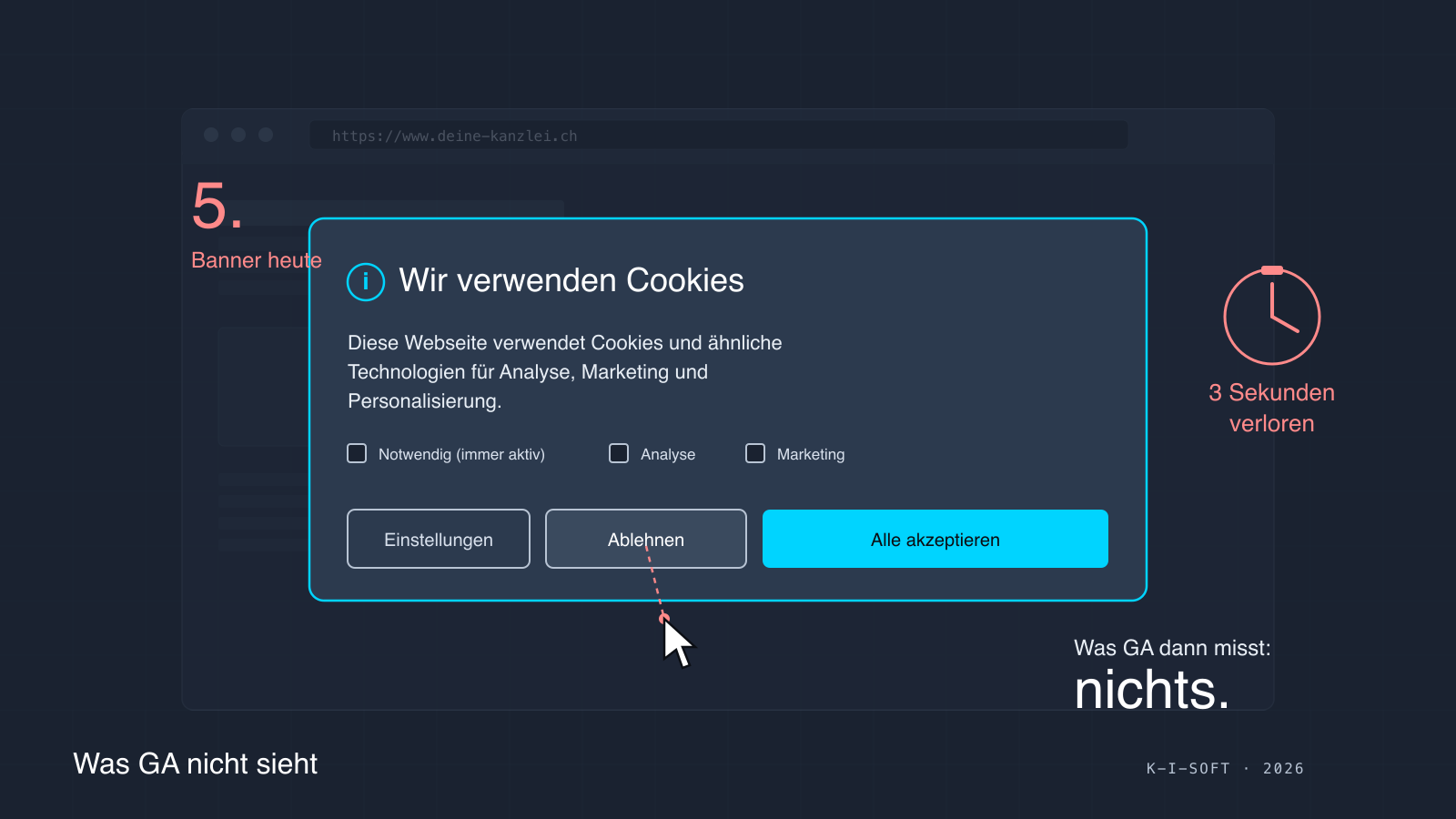
Aktive Zustimmung heisst: der Besucher muss den „Akzeptieren”-Knopf bewusst anklicken. Ein still angeklicktes Banner gilt nicht als Zustimmung. Wegklicken ohne Auswahl gilt nicht. Den Banner ignorieren und weiter scrollen gilt nicht. Und vorab angekreuzte Checkboxen sind seit dem Planet49-Urteil ausdrücklich unwirksam. Wer auf „Ablehnen” klickt oder nicht entscheidet, wird von GA und allen vergleichbaren Tools nicht erfasst, und das ist nicht ein Konfigurationsproblem der Webseite, sondern die rechtlich gewollte Konsequenz.
Wichtig für den weiteren Verlauf dieses Beitrags: der „Ablehnen”-Knopf muss gleich gross, gleich prominent und auf der ersten Ebene des Banners sichtbar sein. Versteckte oder kleinere Ablehnen-Optionen gelten als unwirksame Zustimmung und ziehen Bussgeldrisiko nach sich. Die französische Aufsicht CNIL hat 2022 unter anderem deshalb 150 Millionen Euro gegen Google und 60 Millionen gegen Facebook verhängt.
Erste Ursache: der Consent-Banner
Seit Inkrafttreten der DSGVO 2018 und der angepassten Schweizer Auslegung des revidierten DSG dürfen nicht-essentielle Cookies in der DACH-Region nur nach ausdrücklicher Zustimmung gesetzt werden. Google Analytics gehört dazu. Wer den Banner nicht akzeptiert, wird von GA nicht erfasst, und der Trend der vergangenen Jahre geht eindeutig in eine Richtung.
Eine Übersicht von 26 Banner-Studien aus Europa zeigt den Verlauf: 2018 klickten zwischen 60 und 90 Prozent der Besucher auf „Alles akzeptieren”, oft mangels echter Alternative. Ab 2021 stiegen die Ablehnungsraten auf 40 bis 50 Prozent, sobald Banner einen sichtbaren „Ablehnen”-Knopf zeigen mussten. In den aktuellen Studien von 2024 und 2025 lehnt die Hälfte bis zwei Drittel ab, wenn der Banner korrekt aufgebaut ist. Eine deutsche Erhebung berichtet, dass mittlerweile rund 52 Prozent der Webseiten einen gleichwertig sichtbaren „Ablehnen”-Knopf zeigen, was die Ablehnungsrate weiter nach oben treibt.
Für Schweizer Webseiten ist die Lage strukturell identisch. Eine Verhaltensstudie von Advance Metrics aus 2023 vergleicht das Klickverhalten in mehreren Ländern und stellt fest, dass Nutzer in Deutschland und der Schweiz beim Umgang mit Bannern vergleichbar reagieren, mit einer leichten Tendenz zu noch zurückhaltenderem Verhalten in der Schweiz. Wer also in einem realistischen Monatsbericht für einen Schweizer KMU eine Consent-Rate von 50 Prozent oder weniger ausweist, liegt nicht falsch, sondern realistisch.
Wichtig: dieser Effekt ist nicht das Ergebnis einer schlecht konfigurierten Webseite. Er ist die rechtlich gewollte Konsequenz eines opt-in-Modells, das funktioniert. Wer den Banner mit „Dark Patterns” wieder aufweicht, etwa durch versteckte Ablehnen-Optionen, fängt sich nicht nur Bussgeldrisiken ein. Er gewinnt auch nur kurzfristig: die nachgemessene Vertrauensdelle bei den Besuchern ist meist teurer als die paar Prozentpunkte Consent.
Für die Praxis heisst das: rechne damit, dass mindestens die Hälfte aller Besucher nie in GA erscheint, selbst dann nicht, wenn alles richtig konfiguriert ist.
Zweite Ursache: Browser, die Tracking standardmässig blockieren
Die zweite Schicht ist technisch und liegt ausserhalb der Kontrolle des Webseitenbetreibers. Safari und Firefox verfügen seit Jahren über eingebauten Tracking-Schutz: Intelligent Tracking Prevention (Apple) und Enhanced Tracking Protection (Mozilla). Beide blockieren standardmässig Drittanbieter-Cookies und schränken die Lebensdauer von Erstanbieter-Cookies stark ein. GA arbeitet trotz aller Anpassungen weiterhin in Teilen auf Cookie-Basis und verliert dadurch auch dann Datenpunkte, wenn der Besucher dem Banner zugestimmt hat.
Der Anteil dieser Browser ist je nach Region und Zielgruppe sehr unterschiedlich. In B2B-Umgebungen mit hohem Apple-Anteil (Anwaltskanzleien, Designagenturen, Treuhandbüros, Architekturbüros) liegt der Safari-Anteil oft über 30 Prozent. Bei diesen Besuchern misst GA strukturell ungenauer.
Das ist keine theoretische Behauptung. Die Effekte sind dokumentiert und werden von jedem CMP-Anbieter sowie von Google selbst eingeräumt. Google hat darauf mit „Consent Mode v2” reagiert, einer Modellierung, die fehlende Datenpunkte statistisch schätzt. Modellierte Daten sind eine Annäherung, kein Ersatz für eine echte Messung.
Dritte Ursache: KI-Crawler, die GA nie sieht
Die dritte Schicht ist die jüngste und für die nächsten Jahre die mit Abstand wichtigste. Sie betrifft nicht Menschen, sondern Maschinen, die Webseiten lesen, um Antworten in KI-Chats zu generieren. Wer in ChatGPT „Welche Treuhänder gibt es in Bern” fragt, bekommt eine Antwort, die auf Webseiten basiert, die ein Crawler vorher gelesen und einem Sprachmodell zugänglich gemacht hat. Wer dort nicht erscheint, existiert für die wachsende Zahl von Menschen, die ihre Suche nicht mehr bei Google starten, schlicht nicht.
Diese Crawler heissen GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, AppleBot-Extended und einige weitere. Sie sind kein Randphänomen. GPTBot allein erzeugte im Netzwerk von Vercel innerhalb eines Monats 569 Millionen Anfragen, Anthropics Claude folgte mit 370 Millionen. Zusammen sind das rund 20 Prozent des Volumens von Googlebot mit 4,5 Milliarden Anfragen im selben Zeitraum. Tendenz: steil ansteigend.
Hier kommt der für Webseitenbetreiber entscheidende Punkt. Diese Crawler tauchen in Google Analytics nicht auf. GA bemisst Menschen, nicht Maschinen, und stützt sich auf JavaScript-Ausführung. Vercel und MERJ haben über 500 Millionen GPTBot-Abrufe analysiert und kein einziges Mal JavaScript-Ausführung festgestellt. Dasselbe gilt für ClaudeBot, PerplexityBot, Metas ExternalAgent und Bytespider. Diese Bots laden die Seite, fetchen mitunter sogar JavaScript-Dateien, aber sie führen den Code nicht aus. Sie lesen das rohe HTML und nichts weiter.
Für Techniker: das hat eine direkte Konsequenz für Architektur-Entscheidungen. Eine reine Single-Page-Application, die ihren Inhalt erst nach Hydration im Browser rendert, ist für diese Bots unsichtbar. Inhalt einer client-seitig gerenderten React-, Vue- oder Angular-Anwendung existiert in der Sicht der KI-Crawler nicht. Nicht „schlecht indexiert”. Nicht „teilweise sichtbar”. Unsichtbar. Server-Side-Rendering, Static Site Generation oder ein Hybrid wie Astro mit selektiver Hydration sind nicht mehr nur eine SEO-Optimierung, sondern eine Voraussetzung dafür, in der KI-getriebenen Suche überhaupt vorzukommen. Googles eigener Crawler ist die einzige relevante Ausnahme, er rendert JavaScript mit einem zweistufigen Indexierungsprozess. Bing rendert teilweise. Alle anderen lesen statisches HTML, und damit endet die Geschichte.
Für Geschäftsführer und Marketing-Agenturen: dieser Punkt ist nicht akademisch. Wenn eine moderne Suche („beste Treuhandkanzlei für GmbHs in Bern”) nicht mehr bei Google startet, sondern in ChatGPT oder Perplexity, dann zählt nicht mehr, wie gut die Seite in Googles Ergebnisliste platziert ist, sondern ob KI-Modelle sie überhaupt gelesen haben. Die einzige verlässliche Art, das zu prüfen, sind die Server-Logs der Webseite. Google Analytics zeigt diesen ganzen Verkehr per Design nicht an.
Was die Lücke konkret bedeutet
Drei Effekte ergeben sich aus den drei Ursachen, alle drei real und auf jeder typischen KMU-Webseite messbar.
Erstens: die in GA ausgewiesene Besucherzahl ist eine Untergrenze, nicht der tatsächliche Verkehr. In einem realistischen Szenario mit korrektem Consent-Banner und etwa 30 Prozent Apple-Anteil liegt der tatsächliche Verkehr um den Faktor zwei bis drei über dem GA-Wert. Das ist kein „Vielleicht”, das ist eine Zahl, die in Server-Logs ablesbar ist.
Zweitens: Conversion-Quoten in GA wirken oft besser als sie sind. Wer die Conversion auf 100 GA-Sitzungen rechnet, in Wahrheit aber 200 Besucher hatte, verkennt seinen tatsächlichen Trichter. Für Marketing-Budgets bedeutet das, dass die Kosten pro echtem Besucher in der Regel niedriger sind als ausgewiesen, die Conversion-Rate aber auch geringer.
Drittens: die KI-Crawler-Sichtbarkeit ist in GA überhaupt nicht abbildbar. Wer wissen will, ob ChatGPT seine Webseite gelesen hat, kann das in GA nicht herausfinden, weder durch ein anderes Setup noch durch ein anderes Tool, das auf JavaScript basiert.
Was eine ehrliche Messung leisten kann
Wer diese Lücken schliessen will, ohne GA abzulösen, hat genau eine zuverlässige Option: serverseitige Messung. Jeder Aufruf einer Webseite passiert zuerst einen Server. Bevor JavaScript geladen, ein Banner angezeigt oder ein Cookie gesetzt wird, gibt es einen HTTP-Request, der auf der Seite des Betreibers ankommt. Dieser Request wird unabhängig von Consent, Browser-Einstellung oder JavaScript-Fähigkeit protokolliert. Er erfasst Mensch und Maschine gleichermassen.
Für Techniker: in einer typischen modernen Architektur kommt dieser Request bei einem CDN an. Bei AWS heisst dieses CDN CloudFront, vergleichbare Dienste sind Cloudflare oder Fastly. Alle drei bieten Standard-Access-Logs, die jeden Request mit Zeitstempel, IP-Adresse (verkürzt oder gehasht zur Datensparsamkeit), HTTP-Status, URL und User-Agent festhalten. Diese Logs landen in einem Objektspeicher (bei AWS in S3) und können entweder per Lambda-Funktion in eine Datenbank wie DynamoDB überführt oder direkt mit Tools wie AWS Athena abgefragt werden.
Diese Architektur hat drei Eigenschaften, die für KMU besonders relevant sind. Erstens ist sie datensparsam. Es fliessen keine personenbezogenen Daten in dem Sinn, in dem GA sie verarbeitet, keine Cookies, kein Fingerprinting. Die Logs zeigen, welche Art von Anfrage auf welche URL kam, nicht „Anna aus Bern hat die Seite besucht”. Damit fällt sie aus dem typischen Consent-Pflicht-Bereich von DSGVO und revDSG weitgehend heraus, eine Einordnung, die der jeweilige Datenschutzbeauftragte natürlich für den konkreten Fall bestätigen muss.
Zweitens ist sie günstig. Die Speicherkosten für CloudFront-Logs einer KMU-Webseite liegen typischerweise unter einem Franken pro Monat. Die Verarbeitung kostet je nach Volumen wenige Franken zusätzlich.
Drittens ist sie vollständig in dem Sinn, in dem GA es nicht ist. Jeder einzelne Aufruf erscheint, ob er von einem Menschen oder einem Bot kommt, ob mit oder ohne Consent. Was die Logs nicht zeigen, sind Verhaltensdaten innerhalb der Seite: Klicks, Scrolltiefe, Zeit auf der Seite. Dafür braucht es weiterhin ein clientseitiges Tool, und dafür ist Google Analytics auch nach allen Einschränkungen weiterhin ein guter Standard.
Was server-seitige Messung nicht ersetzt
Damit kein falscher Eindruck entsteht: Server-Logs sind keine Wunderlösung und ersetzen kein vollständiges Analytics-Setup. Was sie nicht können:
Sie messen kein Verhalten innerhalb einer Seite. Wer wissen will, wie lange jemand gelesen hat, wo er weggeklickt ist oder ob er ein Formular halb ausgefüllt und dann abgebrochen hat, braucht weiter ein Tool, das im Browser läuft, mit allen damit verbundenen Consent-Implikationen.
Sie liefern keine fertigen Funnels. Wer einen Kampagnen-Funnel von Werbung zu Conversion auswerten will, braucht weiterhin GA oder ein vergleichbares Tool.
Sie ersetzen nicht das Google-Ads- oder LinkedIn-Conversion-Tracking, das für die Optimierung bezahlter Werbung notwendig ist.
Server-Logs sind eine zweite Ebene neben GA, nicht ein Ersatz. Sie schliessen die Lücke, die GA per Design hat, und liefern den blinden Fleck, den keine Konfiguration und kein Wechsel des Analytics-Tools beheben kann.
Praktische erste Schritte
Drei Schritte, die für die meisten KMU sinnvoll sind, unabhängig von der bisherigen Setup-Tiefe.
Erstens: einmal nüchtern auf den eigenen Consent-Banner schauen. Hat er einen sichtbaren „Ablehnen”-Knopf, der gleich gross und gleich prominent ist wie der „Akzeptieren”-Knopf? Wenn nicht, ist die Webseite formal angreifbar, und das mittlere Bussgeldrisiko reicht von vier- bis fünfstellig. Wenn ja: dann ist eine GA-Erfassung von unter 50 Prozent normal und kein Konfigurationsproblem.
Zweitens: einmal nüchtern auf den Inhalt der Webseite schauen, so wie ein KI-Crawler ihn sieht. Im Chrome-Browser lässt sich mit Rechtsklick „Seitenquelltext anzeigen” der rohe HTML-Quellcode öffnen. Wenn dort der eigentliche Inhalt fehlt und nur ein leeres <div id="root"></div> mit Skripten zu sehen ist, dann ist die Webseite für jeden KI-Crawler unsichtbar. Das ist heilbar, aber es ist gut, vor jedem Folgegespräch mit Agentur oder Entwickler zu wissen, ob das Problem besteht.
Drittens: einmal mit dem technischen Partner (Agentur, Entwickler, IT-Dienstleister) sprechen, ob die Webseite ihre Inhalte serverseitig oder client-seitig rendert, und ob die Server-Logs zugänglich und auswertbar sind. Wenn nicht, ist das kein Drama, aber es ist eine Architektur-Entscheidung, die mit ein paar Monaten Vorlauf gewechselt werden kann. Wer in zwei Jahren in KI-Suchen vorkommen will, sollte die Frage jetzt stellen.
Ich habe die Kernpunkte dieses Beitrags auf einer Seite zusammengefasst: was Google Analytics nicht sieht, und wo die fehlende Hälfte stattdessen sichtbar wird. Als PDF zum Ausdrucken oder Weitergeben.
→ PDF herunterladen: K-I-Soft-Referenz „Was GA nicht sieht”
Wer das misst, sieht etwas anderes
Eine kurze Anekdote zum Schluss, die zugleich ein Test ist. Wer die eigenen Logs zum ersten Mal anschaut, sieht typischerweise drei Dinge, die in GA nie zu sehen waren. Eine Schicht Konkurrenzanalyse: andere Webseiten, oft direkte Mitbewerber, deren Crawler die eigene Seite regelmässig abrufen. Eine Schicht KI-Vorbereitung: GPTBot, ClaudeBot, PerplexityBot, die Inhalte für die nächste Trainings- oder Antwortrunde sammeln. Und eine Schicht echtes menschliches Interesse, das nie zugestimmt hat, am Banner aber dennoch geklickt hat, und das in GA als „nicht erfasst” lebt.
Die meisten Geschäftsführer und Agenturen, die das einmal gesehen haben, gehen nicht zurück zur GA-only-Sicht. Nicht, weil GA falsch ist, sondern weil sie verstanden haben, dass GA seit Jahren genau die Hälfte misst, die man messen darf, und dass die andere Hälfte sich da unten in den Logs bewegt, sichtbar für jeden, der hinschaut.
Quellen
- Vercel: „The rise of the AI crawler” (Volumen GPTBot/Claude/Googlebot, monatliche Anfragezahlen): https://vercel.com/blog/the-rise-of-the-ai-crawler
- Vercel/MERJ-Methodik (Mess-Setup mit Edge-Middleware und Web-Rendering-Monitor): https://vercel.com/blog/how-google-handles-javascript-throughout-the-indexing-process
- Vercel/MERJ: AI-Crawler-JavaScript-Analyse (500 Millionen Abrufe, null Ausführung): https://vercel.com/blog/the-rise-of-the-ai-crawler
- Advance Metrics: „Cookie Behaviour Study, 5 Jahre nach DSGVO” (DACH-Vergleich, Cookie-Verhalten in Deutschland und der Schweiz): https://www.advance-metrics.com/en/blog/cookie-behaviour-study/
- Ignite Video: Übersicht über 26 europäische Banner-Studien (Entwicklung der Ablehnungsraten 2018 bis 2025): https://www.ignite.video/en/articles/basics/cookie-consent-studies
- CookieYes: „Cookie Consent Trends by Country 2026” (Ländervergleich Ablehnungsraten, Bussgeld-Kontext): https://www.cookieyes.com/blog/cookie-consent-trends/
- Searchviu: „AI Crawlers & JavaScript Rendering 2025” (Vergleich Crawler-Verhalten GPTBot vs. ClaudeBot vs. PerplexityBot): https://www.searchviu.com/en/ai-crawlers-javascript-rendering/